
A few weeks ago, we've launched Cube Cloud. We built Cube Cloud to help address some of the most common issues we heard from our users, and in today's blog post, I'd like to show you how and why to migrate to Cube Cloud. With Cube Cloud, you get convenient developer tools and fully managed infrastructure for Cube configured with best practices in mind.
Why should I use Cube Cloud?
First, I want to show you some of the responsibilities you take on when running a self-hosted instance of Cube versus letting Cube Cloud manage the infrastructure for you.
As a busy application developer, time spent on setting up and maintaining various parts of infrastructure is often time taken away from implementing application bug fixes and features. Let's go over some of the reasons benefits Cube Cloud has over a self-hosted Cube installation.
Infrastructure
While Cube is fairly easy to set up, as application developers, we're more interested in managing our application's complexity as opposed to its operational complexity. Cube requires several pieces of infrastructure to work reliably at high scales of both concurrency and data size. This includes:
- Compute resources
- Redis
- Cube Store
- An API gateway
- A refresh worker
- A load balancer
- optionally, a VPC configuration for the above resources

With so many moving parts, you might reduce the deployment complexity by defining your cloud infrastructure as code (e.g., using AWS CDK, Pulumi, or Terraform) and employing a workload orchestrator (e.g., Kubernetes or Nomad). If you have multiple developers working on the project, infrastructure as code would also helps provide them with separate development environments as well as a staging environment before production.
Monitoring and Scaling
At scale, Murphy's Law rings truer than ever, and achieving and maintaining application uptime becomes a serious responsibility. To achieve this with self-hosting, we must ensure that monitoring is configured for Cube, and that we can scale Cube up if there's a spike in traffic.
With Cube Cloud, both monitoring and autoscaling are available out of the box. From a developer perspective, it feels like a serverless experience: nothing to spin up and you're only charged for usage. Cube Cloud is able to determine when a particular resource (e.g., the number of API instances) needs to be scaled, and no fiddling around with instance types and security groups is required, unlike on other cloud platforms.
Monitoring queries sent to your Cube Cloud cluster is easy, just click Queries from the sidebar and et voilà! The entire query history is available, including important metrics such as query result size and time spent, helping you dig into why some queries take longer than others.

Application performance metrics can be found on the Metrics page:


Scaling is just as simple; just make sure the deployment is in Cluster mode and that's it - Cube Cloud will scale up or down based on how many requests are coming in. This is huge for applications with growing datasets or variable traffic.
{kind=link}
Caching
Another scale problem is trying to optimise pre-aggregation build times. Trying to determine the status of configured pre-aggregations, whether they were built or not, when they were built etc. is not usually a one-click operation when self-hosting Cube.
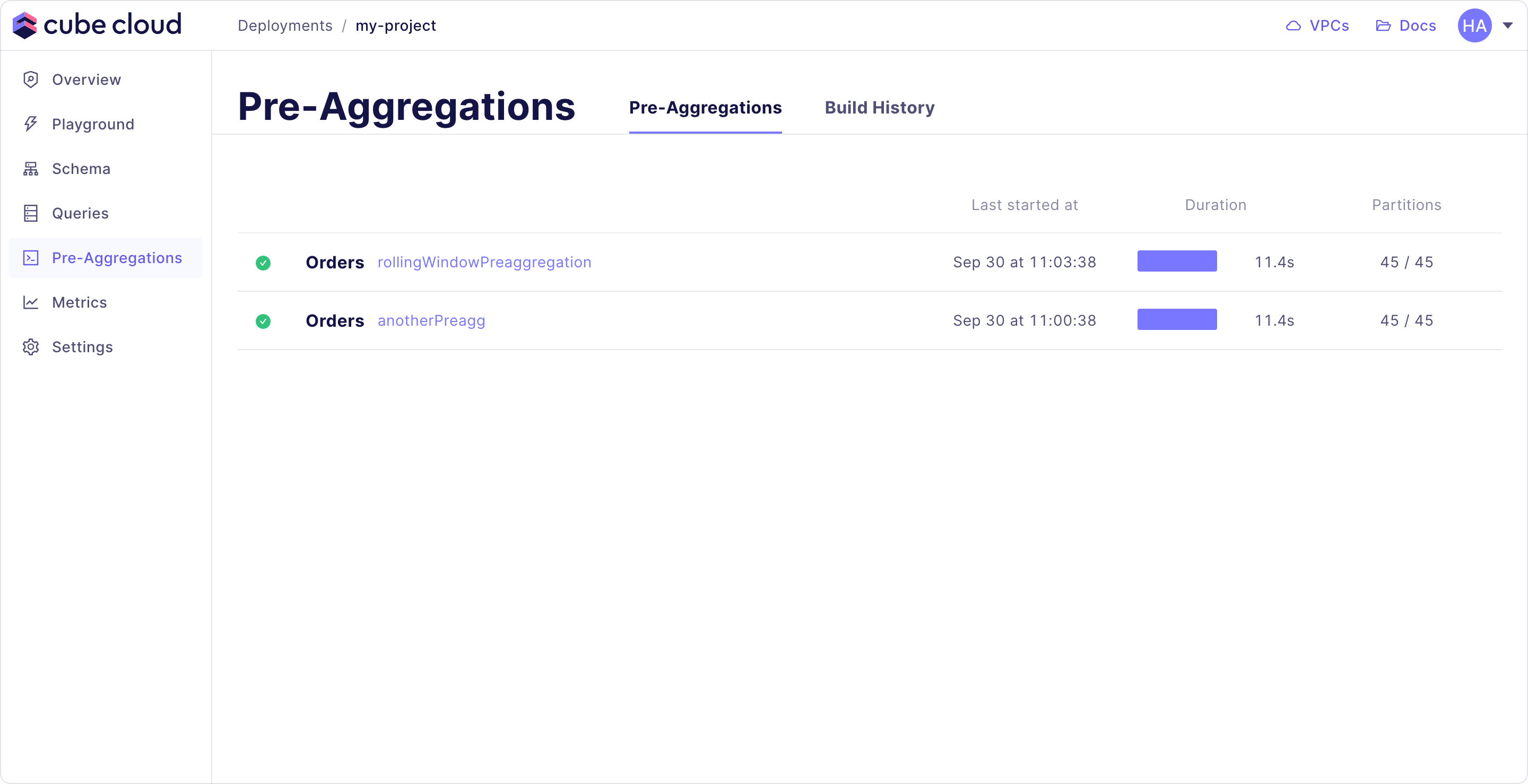
In Cube Cloud, we can check out the Pre-Aggregations page to see the status of all pre-aggregations in our Cube deployment, including whether they're building or not and even which of the partitions, if any, are being refreshed. In production, these pre-aggregations are kept up-to-date automatically for you.
Development Tools
Cube Cloud can watch a GitHub repository for changes and deploy. Connect a deployment to GitHub from the Settings page and you're off to the races.

You can make one-off changes directly in the Cube Cloud console by going to the Schema page and entering Development Mode:

Developers even get their own personal Git branches, complete with a personal API URL and separate pre-aggregations:

Support
For an application with paying customers, having paid support is a lifesaver: if something isn't working properly, developers need to be able to communicate with someone. Cube Cloud comes with support on the Enterprise plan, so you can reach out with an email:

How do I migrate to Cube Cloud?
Now that we've recapped how Cube Cloud compares to self-hosting, let's have a quick look at how we can move a project to Cube Cloud.
GitHub
Cube Cloud has first-class support for repositories hosted on GitHub; start by signing in to your account (if you don't have one, sign up here) and create a new deployment:

Choose the 'Import from a GitHub repository' option and connect your GitHub account to Cube Cloud:
Using a monorepo? Remember to fill in the "Project Directory (for monorepos)" field so Cube Cloud can locate your Cube project inside the Git repository.

On the next page, choose your database and enter its credentials:
Is your database within a VPC? Contact us by clicking on the VPCs button in the top-right.


Git
Not using GitHub to host your repositories? Not a problem; Cube Cloud deployments are de-facto Git repositories. Make sure your deployment is configured to use Git:

Copy the CLI commands and run them in your local copy of the Cube project to add Cube Cloud as an origin. You'll need to generate Git credentials for authentication; you can also do that from the same page.
Authentication
Cube Cloud supports the same JWK-based authentication that's available in open-source Cube; we just need to set a few environment variables first. Let's go to our deployment's settings page, and add the necessary configuration:

Custom domains
Cube Cloud has support for custom domains, too. Add a new CNAME record to your DNS pointing at the host part of your deployment's API URL. In the screenshot below, the CNAME value would be strong-elk.gcp.us-central1.cubecloudapp.dev:

Then come back to Cube Cloud and enter your custom domain, then click the 'Add' button.
Custom NPM packages
Custom packages are disabled by default. Shoot us an email at support@cube.dev to get it enabled for your account
Some Cube projects make use of third-party code from NPM; some projects may use custom drivers for example, or an error logging library such as Sentry. Cube Cloud fully supports installing dependencies from the NPM registry, simply ensure that the required dependencies are listed under the dependencies section of the Cube project's package.json.
Multiple databases
Cube Cloud also supports connecting to multiple databases, just as in the open-source version of Cube. When creating a new deployment, simply skip the database connection wizard and go to the Environment Variables tab on the Settings page. There, simply add the required connection details as variables for each additional database:

Make sure the same environment variables are being used in your cube.js configuration file:

Just like the open-source version of Cube, Cube Cloud can now communicate with however many databases your application needs. 💯
Wrapping up
In an ideal world, I would get to focus solely on the needs of my users, not my infrastructure. Cube Cloud takes care of the infrastructure and provides me with convenient developer tools, letting me put my efforts into creating business value. Cube Cloud has a free tier for development projects and proof-of-concepts, and provides autoscaling, cache storage, and pre-aggregation warm-up along with other features out-of-the-box.
This post aimed to provide some perspectives into why migrating to Cube Cloud is a good investment for your application, as well as demonstrating the ease of moving a self-hosted project to Cube Cloud. It's really easy to deploy and grows with your application, all while minimising your operational responsibilities so you can focus on what matters; your users. Cube Cloud is now open for registration, sign up today by clicking here.
Hope you all enjoyed reading this as much as I enjoyed writing it. Until next time 👋