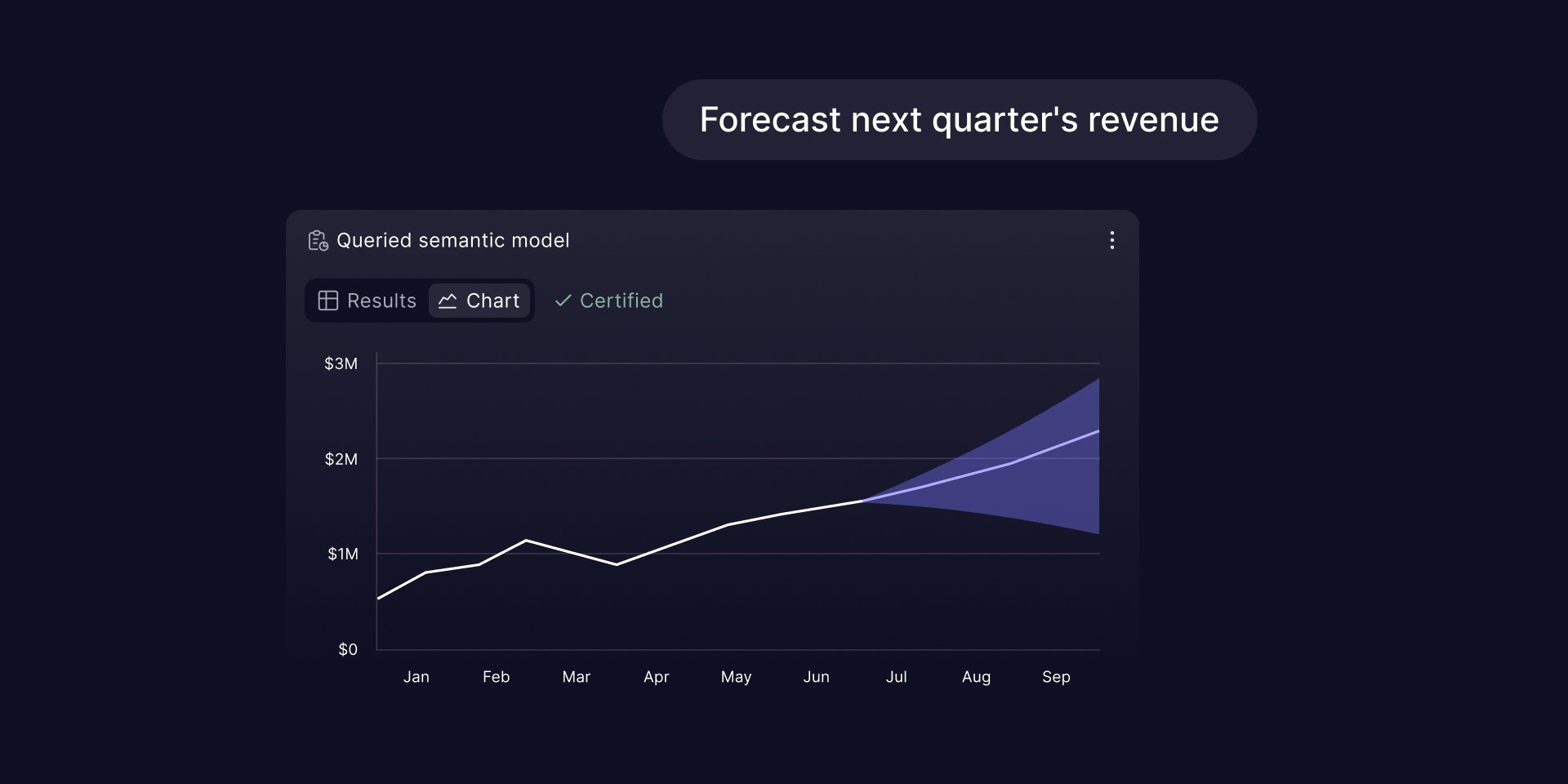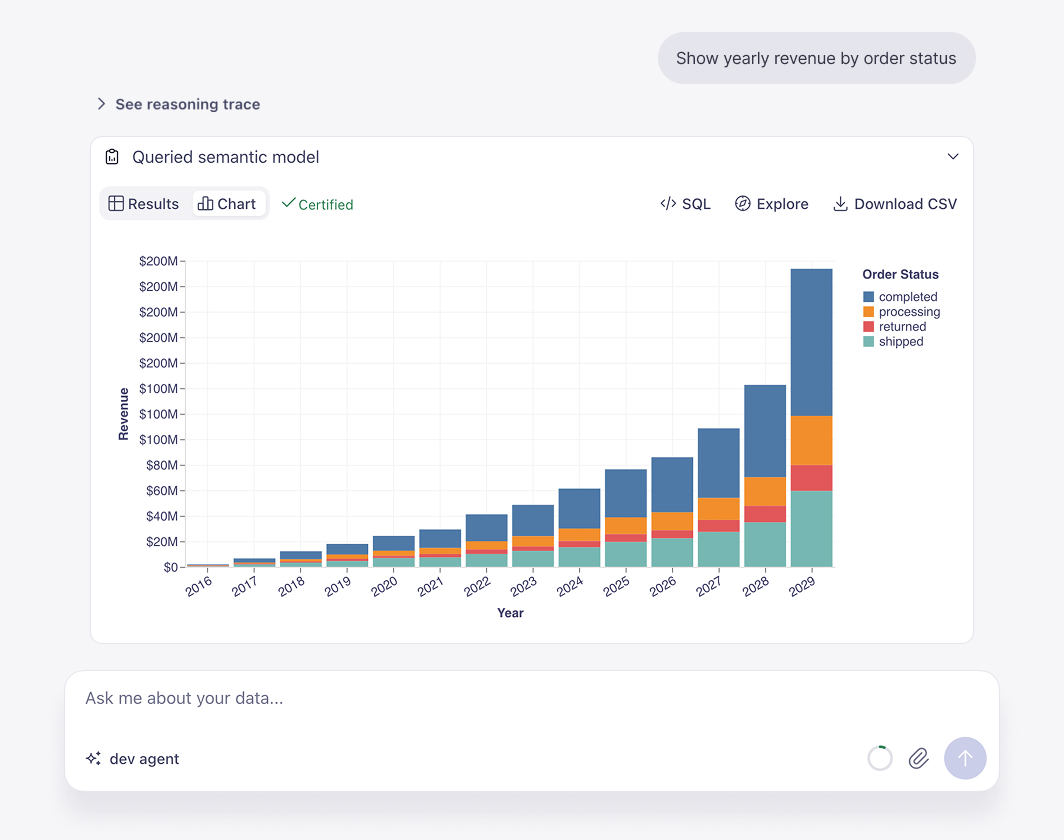
Cube becomes our single source of truth for metric definitions and powers everything from customer-facing dashboards to AI-driven quarterly business reviews. CSMs gain back dozens of hours each quarter, enabled by Cube’s semantic layer and agentic analytics.
Anthony Cronander
Senior Analytics Engineer, Drata