
In this tutorial we'll learn how to add a pivot table to a React app using AG Grid, the self-proclaimed best JavaScript grid in the world.
What is a pivot table?
Pivot tables, also known as multi-dimensional tables or cross-tables, are tables that display the statistical summary of the data in regular flat tables. Often, such tables come from databases, but it's not always easy to make sense of the data in large tables. Pivot tables summarize the data in a meaningful way by aggregating it with sums, averages, or other statistics.
Here's how a pivot table is explained in Wikipedia. Consider you have a flat table like this with e-commerce T-shirt inventory data: regions, ship dates, units, prices, etc.

An inventory might be overwhelmingly lengthy, but we can easily explore the data with a pivot table. Let's say we want to know how many items were shipped to each region on each date. Here's the pivot table that answers exactly to this question:

Analytics 101. Note that how many items is an aggregated, numerical value — a sum of items that were shipped. In analytical applications, such aggregated values are called "measures". Also note that each region and each date are categorial, textual values that can be enumerated. In analytical apps, such categorial values are called "dimensions".
Actually, that's everything one should know about data analytics to work with pivot tables. We'll use this knowledge later.
Why AG Grid?
AG Grid is a feature-rich implementation of a JavaScript data table. It supports React, Angular, and Vue as well as vanilla JavaScript. Honestly, it's no exaggeration to say that it contains every feature possible (for a data table):

AG Grid's authors emphasize that it's particularly useful for building enterprise applications. So, it's understandable that it comes in two versions:
- free and open-source, MIT-licensed Community version
- free-to-evaluate but paid and non-OSS Enterprise version
Almost all features are included in the Community version, but a few are available only as a part of the Enterprise version: server-side row model, Excel export, various tool panels, and — oh, my! — pivoting and grouping.
It's totally okay for the purpose of this tutorial, but make sure to purchase the license if you decide to develop a production app with an AG Grid pivot table.
Here's what our end result will look like:
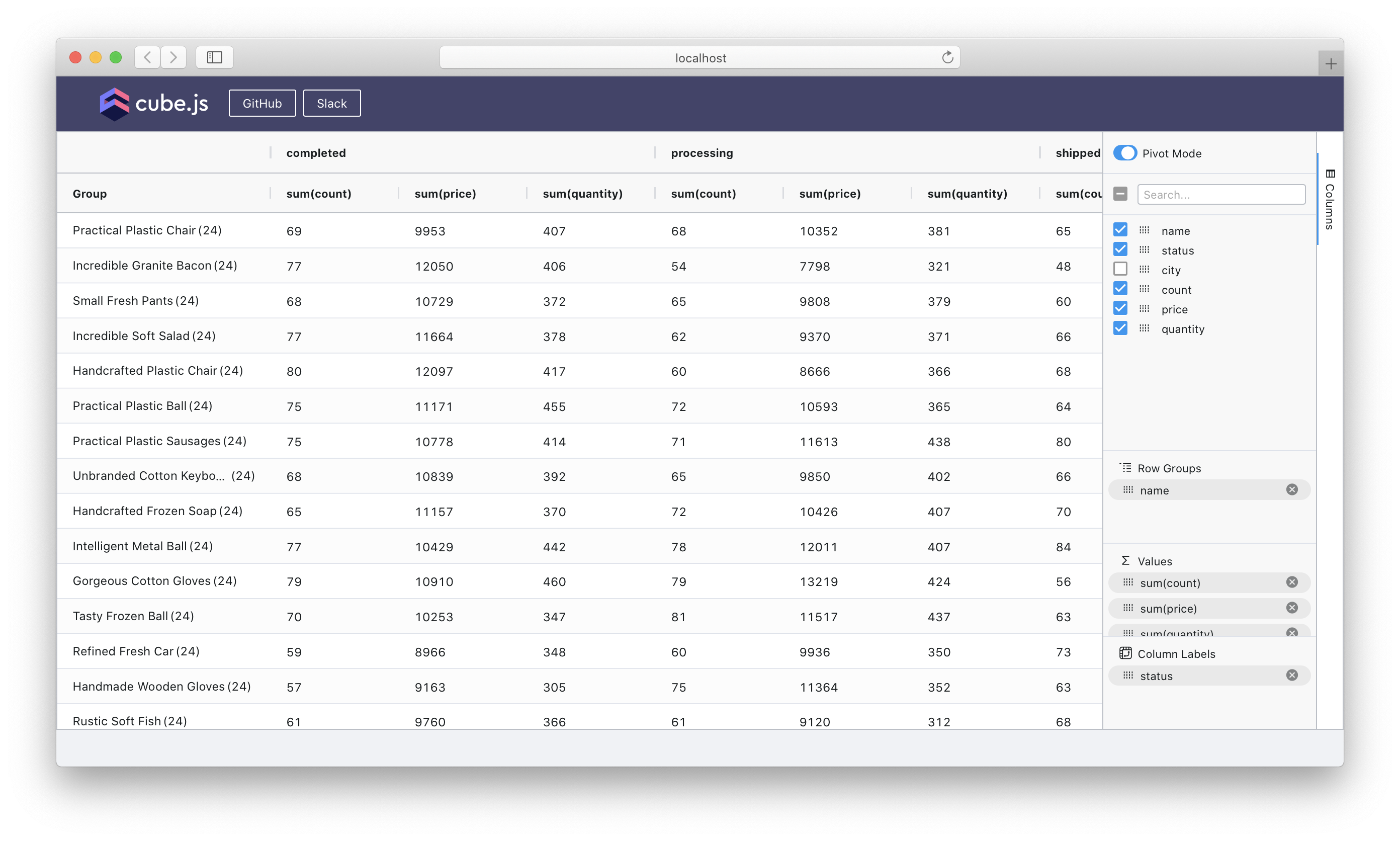
Want to try it? Here's the live demo you can use right away. Also, the full source code is on GitHub.
Now we're all set, so let's pivot! 🔀
How to Create an Analytical API
Pivot tables are useless without the data, and the API is where the data comes from in a real-world app. And the more data we have, the better it is.
So, what are we going to do? We'll use Cube.
Cube is an open-source analytical API platform. It allows you to create an API over any database and use that API in any front-end app. In this tutorial, we'll connect Cube to a database and we'll use the API in our React app.
Cube provides an abstraction called a "semantic layer," or a "data schema," which encapsulates database-specific things, generates SQL queries for you, and lets you use high-level, domain-specific identifiers to work with data.
Also, Cube has a built-in caching layer that provides predictable, low-latency response query times. It means that, regardless of your data volume and database, an API built with Cube will serve data to your app in a performant way and help create a great user experience.
Let's try it in action.
The first step is to create a new Cube project. Here, I assume that you already have Node.js installed on your machine. Note that you can also use Docker to run Cube. Run in your console:
Now you have your new Cube project in the react-pivot-table folder containing a few files. Let's navigate to this folder.
The second step is to add database credentials to the .env file. Cube will pick up its configuration options from this file. Let's put the credentials from a publicly available Postgres database there. Make sure your .env file looks like this, or specify your own credentials:
Here's what all these options mean:
- Obviously,
CUBEJS_DB_TYPEsays we'll be connecting to Postgres. CUBEJS_DB_HOSTandCUBEJS_DB_PORTspecify where our Postgres instance is running, andCUBEJS_DB_SSLturns on secure communications over TLS.CUBEJS_DB_USERandCUBEJS_DB_PASSare used to authenticate the user to Postgres.CUBEJS_DB_NAMEis the database name where all data schemas and data tables are kept together.- The rest of the options configure Cube and have nothing to do with the database.
The third step is to start Cube. Run in your console:
And that's it! Here's what you should see:

Great, the API is up and running. Let's move on! 🔀
How to Explore the Data
Before we can tinker with the data, we need to describe it with a data schema. The data schema is a high-level domain-specific description of your data. It allows you to skip writing SQL queries and rely on Cube to generate them for you.
As the console output suggests, please navigate to localhost:4000 — this application is the Cube Developer Playground. It's able to generate an initial version of the data schema automatically. Go to the "Schema" tab, select all tables under "public", and click the "Generate Schema" button.

That's all. You can check that in the schema folder there's a number of files containing the data schema files: Orders.js, Products.js, Users.js, etc.
Now we have the data schema in place. Let's explore the data!
Go to the "Build" tab, click "+ Dimension" or "+ Measure," and select any number of dimensions and measures. For example, let's select these measures and dimensions:
Orders CountmeasureLine Items PricemeasureLine Items QuantitymeasureProducts NamedimensionOrders StatusdimensionUsers Citydimension
As the result, you should get a complex, lengthy table with the data about our e-commerce enterprise:

Looks interesting, right? Definitely feel free to experiment and try your own queries, measures, dimensions, time dimensions, granularities, and filters.
Take note that, at any time, you can click the "JSON Query" button and see the query being sent to Cube API in JSON format which, essentially lists the measures and dimensions you were selecting in the UI.

Later, we'll use this query to fill our upcoming pivot table with data. So, let's move on and build a pivot table! 🔀
How to Add a Pivot Table
Okay, I'll be honest, Cube Developer Playground has one more feature to be explored and used for the greater good.
Let's go to the "Dashboard App" tab where you can generate the code for a front-end application with a dashboard. There's a variety of templates for different frameworks (React and Angular included) and charting libraries but you can always choose to "create your own".

Let's choose "React", "React Antd Dynamic", "Bizcharts", and click "OK". In just a few seconds you'll have a newly created front-end app in the dashboard-app folder. Click "Start dashboard app" to run it, or do the same by navigating to dashboard-app and running:
Believe it or not, this dashboard app will allow you to run the same queries you've already run the Developer Playground. On the "Explore" tab, you can create a query, tailor the chart, and then click "Add to dashboard". On the "Dashboard" tab, you'll see the result.
Impressive? We'll go further than that, and replace the dashboard with the pivot table right now.
We'll need to follow a series of simple steps to add AG Grid, tune it, review the result, and understand how everything works. I should say that AG Grid has excellent documentation with versions for vanilla JavaScript, React, Angular, and Vue. However, here's an even more condensed version of the steps you need to follow to set up AG Grid.
First, let's install the AG Grid packages. Make sure to switch to the dashboard-app folder now. AG Grid can be installed via packages or modules, but the former way is simpler. Let's run in the console:
Note that we're installing ag-grid-enterprise version. There's also ag-grid-community that contains a subset of the enterprise features but the pivot table feature is included in the enterprise version only. It's going to work but it will print a giant warning in the console until you obtain a license:

Second, let's create a pivot table component. Add a new file at the src/components/Grid.js location with the following contents. Basically, it sets AG Grid up, adds data from Cube API, and does the pivoting. It's not very lengthy, and we'll break this code down in a few minutes:
To make everything work, now go to src/App.js and change a few lines there to add this new Grid component to the view:
Believe it or not, we're all set! 🎉 Feel free to start your dashboard-app again with npm run start and prepare to be amused. Here's our data grid:
You can even turn "Pivot Mode" off with the knob in the top right corner, remove all measures and dimensions from "Row Groups" and "Values", and behold the raw ungrouped and unpivoted data as fetched from Cube API:

Amazing! Let's break the code down and review the features of AG Grid! 🔀
How Everything Works
All relevant code resides inside the src/components/Grid.js component. We'll explore it from top to bottom.
In the imports, you can see this React hook imported from the Cube client React package. We'll use it later to send a query to Cube API:
After that, we'll import AG Grid and its' React integration, which has a convenient AgGridReact component that we'll use. However, in complex scenarios, you'll need to use the [onGridReady](https://www.ag-grid.com/react-grid/grid-interface/#access-the-grid--column-api-1) callback to get access to the Grid API and tinker with it directly. Also, note that AG Grid provides style definitions and a few themes you can import and use.
Next, meet the Cube query in JSON format. I hope you remember this query from Developer Playground where it was available on the "JSON Query" tab:
Now we jump into the functional Grid component. Time for React stuff! Here we define a state variable where we'll store the rows to be displayed in our table. Also, we use the useCubeQuery hook to send the request to Cube API. Then, in useEffect, we get the result, transform it into tabular format with the convenient tablePivot method, and assign it to the state. (Remapping is needed because Cube returns column names in the Cube.measure and Cube.dimension format but AG Grid doesn't work with dots in the names.)
Then we extract the column names from the dataset. We'll use them later:
Time for JSX! Note that the AgGridReact component is wrapped with a div.ag-theme-alpine to apply the custom Ag Grid styles. Also, note how default column styles and properties are set.
The last three lines are the most important ones because they activate the pivot table, enable a convenient sidebar you might know from Excel or similar software, and also wire the row data into the component:
Here's the most complex part. To transform the row data into a pivot table, we need to specify the column or columns used on the left side and on the top side of the table. With the pivot option we specify that data is pivoted (the top side of the table) by the "status" column. With the rowGroup option we specify that the data is grouped by the "name" column.
Also, we use aggFunc to specify the default aggregation function used to queeze the pivoted values into one as sum. Then, we list all allowed aggregation functions under allowedAggFuncs .
Here's how these functions are implemented. Nothing fancy, just a little bit of JavaScript functional code for minimum, maximum, sum, and average:
You can click on "Values" to change the aggregation function used for every column, or set it programmatically as specified above:

And that's all, folks! 🎉 Thanks to AG Grid and Cube, we had to write only a few tiny bits of code to create a pivot table.
I strongly encourage you to spend some time with this pivot table and explore what AG Grid is capable of. You'll find column sorting, a context menu with CSV export, drag-and-drop in the sidebar, and much more. Don't hesitate to check AG Grid docs to learn more about these features.
Thank you for following this tutorial to learn more about Cube, build a pivot table, and explore how to work with AG Grid. I wholeheartedly hope that you enjoyed it 😇
Please don't hesitate to like and bookmark this post, write a comment, and give a star to Cube or AG Grid on GitHub. I hope that you'll try Cube and AG Grid in your next production gig or your next pet project.
Good luck and have fun!


