
ETL stands for Extract, Transform, Load. It has been a traditional way to manage analytics pipelines for decades. With the advent of modern cloud-based data warehouses, such as BigQuery or Redshift, the traditional concept of ETL is changing towards ELT – when you’re running transformations right in the data warehouse. Let’s see why it’s happening, what it means to have ETL vs ELT, and what we can expect in the future.
ETL is hard and outdated
ETL arose to solve a problem of providing businesses with clean and ready-to-analyze data. We remove dirty and irrelevant data and transform, enrich, and reshape the rest. The example of this could be sessionization – the process of creating sessions out of raw pageviews and users’ events.
ETL is complicated, especially the transformation part. It requires at least several months for a small-sized (less than 500 employees) company to get up and running. Once you have the initial transform jobs implemented, never-ending changes and updates will begin, because data always evolves with business.
The other problem of ETL is that during the transformation we reshape data into some specific form. This form usually lacks some data’s resolution and does not include data which is useless for that time or for that particular task. Often, “useless” data becomes “useful.” For example, if business users request daily data instead of weekly, then you will have to fix your transformation process, reshape data, and reload it. That would take a few weeks more.
The more data you have, the longer the transformation process is.
The transformation rules are very complex, and even if you have only a few terabytes of data, loading time can take hours. Given the time it takes to transform and load a big dataset, your end users will almost never get fresh data. “Today” will mean today last week, and “yesterday” – a week ago yesterday. Sometimes it takes several weeks or months to get a new update to rollup.
To summarize some of the cons of ETL:
- ETL is expensive to implement, especially for small and medium businesses.
- ETL is expensive to maintain.
- ETL eliminates access to raw data.
- ETL is time consuming. Users have to wait for transformation to be finished.
Why have we been doing it for decades?
A prior generation of data warehouses weren’t able to work with the size and complexity of raw data. So, we had to transform data before loading and querying it.
The latest advances in database technologies made warehouses much faster and cheaper. Storage is getting more accessible all the time, some data warehouses even separate pricing for storage and computation. For example, BigQuery storage pricing is quite cheap and you can just store all your raw data there.
The most important changes in recent years to data warehouses, which made the comparison of ETL vs ELT possible:
- Optimized for analytical operations. Modern analytical warehouses tend to be columnar and optimized for aggregating and processing huge datasets.
- Cheap storage. No worries about what to store, you can just dump all your raw data into a warehouse.
- Cloud based. It scales infinitely and on-demand, so you can get the performance you need the moment you need it.
ETL vs ELT: running transformations in a data warehouse
What exactly happens when we switch “L” and “T”? With new, fast data warehouses some of the transformation can be done at query time. But there are still a lot of cases where it would take quite a long time to perform huge calculations. So instead of doing these transformations at query time you can perform them in the warehouse, but in the background, after loading data.
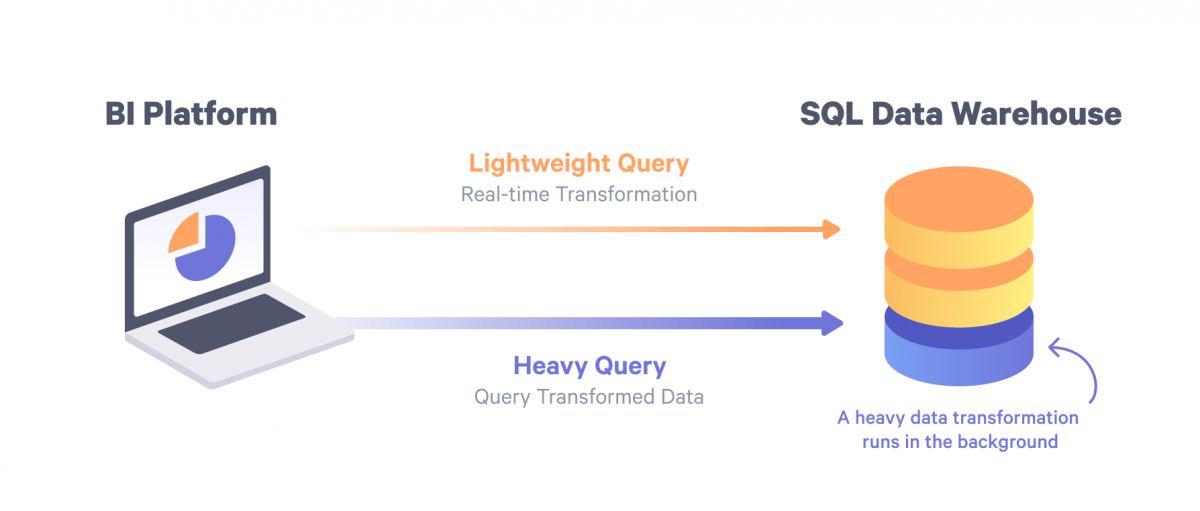
Once raw data is loaded into a warehouse, heavy transformations can be performed. It makes sense to have both real-time and background transformations in the BI platform. Users consume and operate on the business definitions level when querying data, and BI is either performing transformation on-the-fly or querying data already transformed in the background.
This approach gives flexibility and agility for development of a transformation layer.
Software engineers nowadays deploy several times a day and praise continuous delivery. The same principle should be adopted for how we approach a transformation. If metric definition changes or some new data is required, one can easily make this changes in hours, not weeks or months. It is especially valuable for fast-growing startups, where changes happen daily and data teams have to be flexible and agile to keep up with product development and business needs.
As data warehouses advance more and more, I’m sure we will see how query time transformations will entirely replace background transformations. Before that happens, we can run some transformations in the background with ELT. Since they are already SQL based and run in the data warehouses, the final switch would be easy and painless.
Statsbot is designed to work with raw data stored in modern data warehouses and run both query time and background transformations. Don’t hesitate to contact us and try it for free.
