
This is the first part of a tutorial series on building an analytical web application with Cube.js. It expects the reader to be familiar with Javascript, Node.js, React, and have basic knowledge of SQL. The final source code is available here and the live demo is here. The example app is serverless and running on AWS Lambda. It displays data about its own usage.
There is a category of analytics tools like Mixpanel or Amplitude, which are good at working with events data. They are ideal for measuring product or engagement metrics, such as activation funnels or retention. They are also very useful for measuring A/B tests.
Although all these tools do a job, they are proprietary and cloud-based. That could be a problem when privacy is a concern. Or if one wants to customize how funnels or retention work under the hood. While traditional BI tools, like Tableau or Power BI, could potentially be used to run the same analysis, they can not offer the same level of user experience. The problem is that they are designed to be general business intelligence tools, and not specific for funnels, retention, A/B tests, etc.
With recent advancements in frontend development, it became possible to rapidly develop complex user interfaces. Things which took a week to build five years ago could be built in an afternoon nowadays. On the backend and infrastructure side, cloud-based MPP databases, such as BigQuery and Athena, are dramatically changing the landscape. The ELT approach, when data is transformed inside the database, is getting more and more popular, replacing traditional ETL. Serverless architecture makes it possible to easily deploy and scale applications.
All of these made it possible to build internal alternatives to established services like Mixpanel, Amplitude, or Kissmetrics. In this series of tutorials, we’re going to build a full-featured open-source event analytics system.
It will include the following features:
- Data collection;
- Dashboarding;
- Ad hoc analysis with query builder;
- Funnel analysis;
- Retention analysis;
- Serverless deployment;
- A/B tests;
- Real-time events monitoring;
The diagram below shows the architecture of our application:
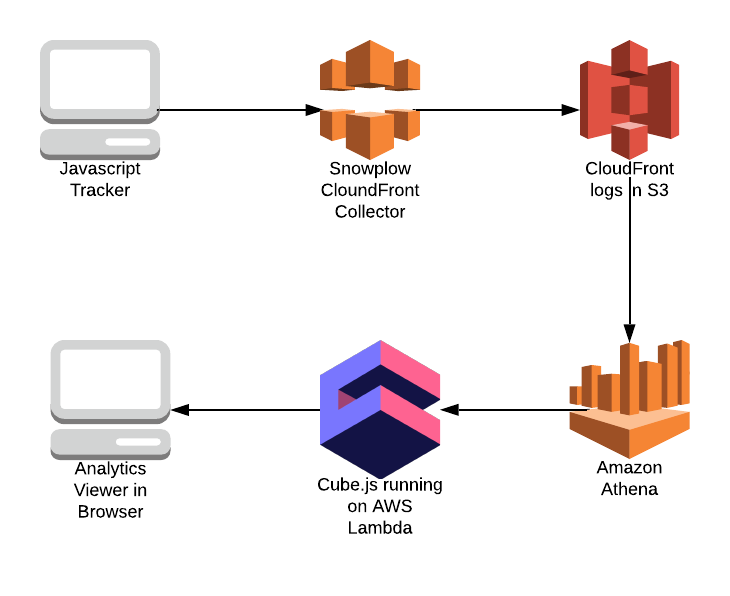
In the first part of our tutorial, we’ll focus more on how to collect and store data. And briefly cover how to make a simple chart based on this data. The following parts focus more on querying data and building various analytics reporting features.
Collecting Events
We’re going to use Snowplow Cloudfront Collector and Javascript Tracker. We need to upload a tracking pixel to Amazon CloudFront CDN. The Snowplow Tracker sends data to the collector by making a GET request for the pixel and passing data as a query string parameter. The CloudFront Collector uses CloudFront logging to record the request (including the query string) to an S3 bucket.
Next, we need to install Javascript Tracker. Here is the full guide.
But, in short, it is similar to Google Analytics’s tracking code or Mixpanel’s, so we need to just embed it into our HTML page.
Here you can find how it is embedded into our example application.
Once we have our data, which is CloudFront logs, in the S3 bucket, we can query it with Athena. All we need to do is create a table for CloudFront logs.
Copy and paste the following DDL statement into the Athena console. Modify the LOCATION for the S3 bucket that stores your logs.
Now we are ready to connect Cube.js to Athena and start building our first dashboard.
Building Our First Chart
First, install Cube.js CLI. It is used for various Cube.js workflows.
Next, сreate a new Cube.js service by running the following command. Note, we are specifying Athena as a database here (-d athena) and template as serveless (-t serverless). Cube.js supports different configurations, but for this tutorial, we will use the serverless one.
Once run, the create command will create a new project directory that contains the scaffolding for your new Cube.js project. This includes all the files necessary to spin up the Cube.js backend, example frontend code for displaying the results of Cube.js queries in a React app, and some example schema files to highlight the format of the Cube.js Data Schema layer.
The .env file in this project directory contains placeholders for the relevant database credentials. For Athena, you'll need to specify the AWS access and secret keys with the access necessary to run Athena queries, and the target AWS region and S3 output location where query results are stored.
Now, let’s create a basic Cube.js Schema for our events model. Cube.js uses Data Schema to generate and execute SQL; you can read more about it here.
Create a schema/Events.js file with the following content.
In the schema file, we create an Events cube. It is going to contain all the information about our events. In the base SQL statement, we’re extracting values from the query string sent by the tracker by using the regexp function. Cube.js is good at running transformations such this and it could also materialize some of them for performance optimization. We’ll talk about it in the next parts of our tutorial.
With this schema in place, we can run our dev server and build the first chart.
Spin up the development server by running the following command.
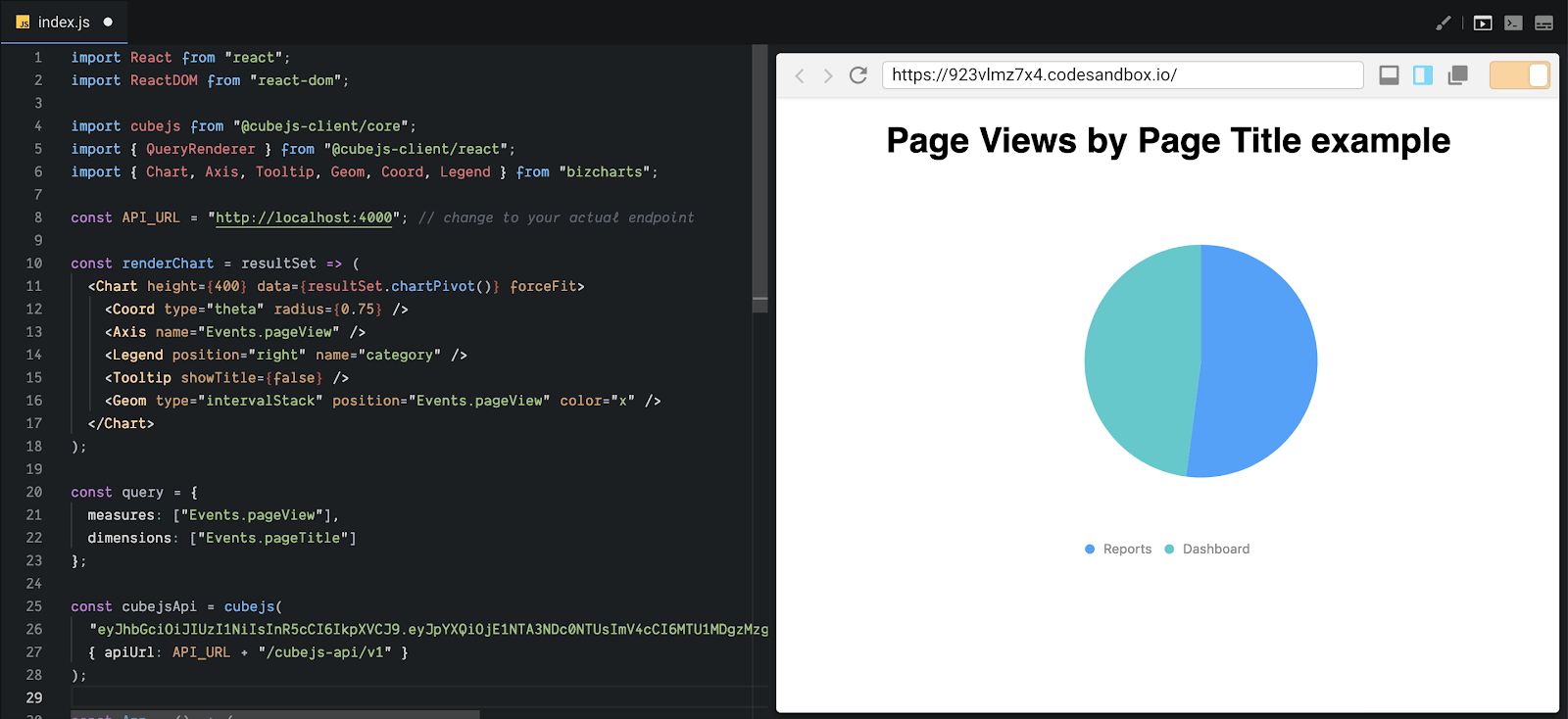
Visit http://localhost:4000, it should open a CodeSandbox with an example. Change the renderChart function and the query variable to the following.
Now, you should be able to see the pie chart, depending on what data you have in your S3.
In the next part, we’ll walk through how to build Conversion Funnels. In the third part we will make a dashboard and dynamic query builder, like one in Mixpanel or Amplitude. Part 3 will cover Retention Analysis. In the final part, we will discuss how to deploy the whole application in the serverless mode to AWS Lambda.
You can check out the full source code of the application here.