In the following tutorial, I’ll show you how to create a basic analytics dashboard with Node, Express, and Cube. As a database, we’re going to use MongoDB with MongoDB BI Connector. If you’re not familiar with it, I highly recommend you go through the Building a MongoDB Dashboard tutorial. It covers the basics of setting up Mongo and its BI Connector.
DEPRECATION WARNING. As of November 2020, embedding Cube.js into Express application is strongly discouraged due to performance and reliability considerations. Please check the deployment guide to learn more about running a standalone Cube.js installation in a Docker container, as a serverless function, and more. Also, have a look at the serverless setup described below in this tutorial.
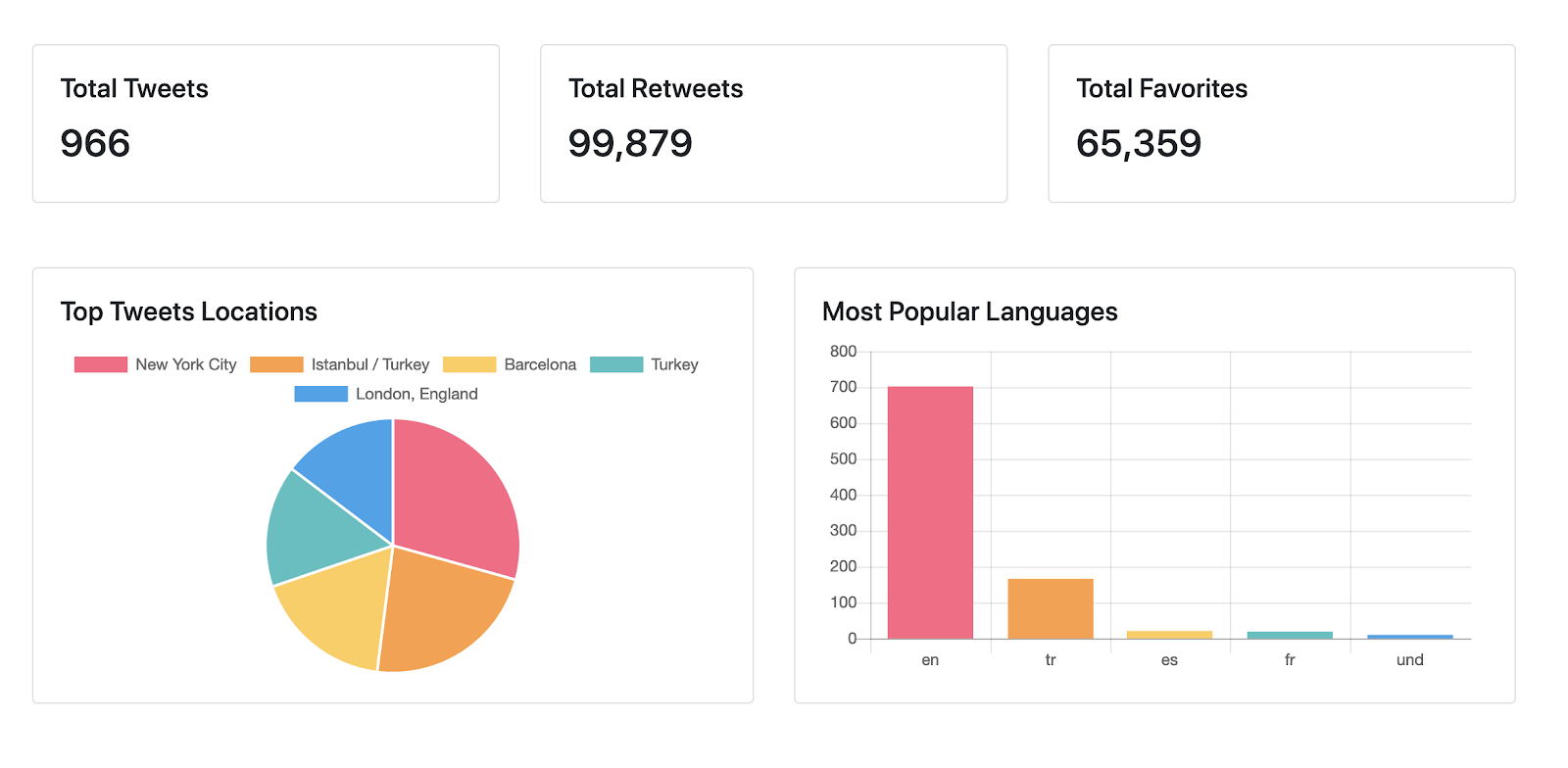
Here how the final dashboard would look:
Getting a Sample Dataset
You can skip this step if you already have some data for your dashboard
If you don’t have a local MongoDB instance, please download it here. The BI Connector can be downloaded here.
There is a good repository on Github with a curated list of JSON / BSON datasets from the web in order to practice in MongoDB. We’ll pick a tweets dataset for our dashboard.
Download test data and import it using the following command in your MongoDB directory.
Now make sure both MongoDB and MongoDB BI Connector processes are running.
Setting up a Backend
We’ll use an express application generator to create an application skeleton.
Next, create a new express app with the view engine set to Handlebars (hbs).
We’re going to use an open source framework, Cube as our analytical backend. It generates and executes SQL queries, as well as provides caching, data pre-aggregation, security, and API to query results and build visualizations. You can learn more about it here.
Cube can be easily embedded into an Express application. Let’s add it to our project dependencies.
We’ve added a core server package for Cube and the Cube MongoBI driver. We’ve also added a dotenv package to manage our credentials. Let’s create a .env file with the following credentials; we need them to tell Cube how to connect to Mongo.
Now, let’s mount the Cube.js Server into our express application. Add the following code right after the routes declaration in your app.js.
With the above two lines of code, we have loaded all required configs from the .env file and mounted Cube.js into our Express app. By default, it’s mounted into the /cubejs-api/v1/ path namespace. But you can change it and a lot of other things by passing the configuration object to the CubejsServerCore.create() method. We’ll keep the default settings for our tutorial.
Now, let’s create a Cube.js Schema for our tweets table. Cube.js uses Data Schema to generate and execute SQL; you can read more about it here.
Create a folder, schema, with a Tweets.js file inside with the following content.
In Cube.js, you can describe your queries in Javascript and then they will be compiled into SQL and executed inside your database. It uses measures and dimensions as basic units to describe various analytics queries. This tutorial is a good place to get started with Cube.js Schema.
Now let’s move on to building a dashboard on the frontend.
Alternative Setup: Run Cube.js in Serverless Mode
If you want to run it as a microservice or as a serverless function - use Cube.js CLI. The code below shows how you can generate a new Cube.js app with Cube.js CLI:
It will create a new project pre-configured to be deployed to AWS Lambda with Serverless framework. You can learn more about Cube.js serverless deployment here.
Building Analytics Dashboard
We’ll use Bootstrap for styling, the Cube.js client to load data, and Chart.js to display it.
Replace the content of views/index.hbs with the following.
Let’s break this down into pieces. First, we’re loading our required libraries. The Cube.js client could be installed in different ways, here we’re just loading a UMD build from CDN. We’re also loading Bootstrap, Chart.js, and numeral.js to format numbers from CDN.
The next part is just a plain HTML markup with the Bootstrap grid.
The last part is where we load and display data in our dashboard widgets. For the sake of this tutorial, we don’t use any frontend libraries. But, if you want, Cube.js has bindings for all popular frontend frameworks, such as React.
First, we’re initializing the Cube.js client and passing an API Token and API URL. In the development environment, Cube.js doesn't enforce the use of the token to authorize queries, so you can use any string for your token here. You can learn more about using and generating tokens in the production environment here in the docs. The URL should be the same.
Next, we’re loading and displaying data for the upper row of the dashboard, the KPIs section. Here we display just the plain numbers with some formatting done by numeral.js.
The row has one pie and one bar chart, plotted with Chart.js. To display the bar chart, we’re requesting the Tweets.count measure and grouping it by the Tweets.location dimension. We’re also applying a filter to exclude tweets with an empty location. Finally, we’re setting the limit to 5 to get only the top 5 locations.
You can learn more about the Cube.js Query format here.
For the bar chart, we’re doing a similar grouping, but instead of location, we’re grouping by the Tweets.lang dimension.
Now, to see the dashboard in action, start your server.
And visit http://localhost:3000 to see your analytics dashboard in action. Also, we have a live demo of the app here. The full source code is available on Github.
Why Cube.js
Why is using Cube.js better than hitting MongoDB directly with SQL queries? Cube.js solves a plethora of different problems every production-ready analytic application needs to solve: analytic SQL generation, query results caching and execution orchestration, data pre-aggregation, security, API for query results fetch, and visualization.

These features allow you to build production-grade analytics applications that are able to handle thousands of concurrent users and billions of data points. They also allow you to do analytics on a production MongoDB read replica or even a MongoDB main node due to their ability to reduce the amount of actual queries issued to a MongoDB instance.