
In this tutorial we'll explore how to build an analytical application on top of Google BigQuery, a serverless data warehouse, and use a few public datasets to visualize the impact of the COVID-19 pandemic on people's lives.
What is Google BigQuery?
Before you can ask, here's the application we're going to build:

And not only for the United States but for every country.
Now to BigQuery! BigQuery is a serverless big data warehouse available as a part of Google Cloud Platform. It's highly scalable, meaning that it can process tiny datasets as well as petabytes of data in seconds, using more cloud capacity as needed. (However, due to BigQuery's distributed architecture, you can't possibly expect it to have a sub-second query response time.)
BigQuery has a gentle learning curve, in part due to its excellent support for SQL, although (big surprise!) we won't be writing SQL queries in this tutorial.
BigQuery also has a free usage tier: you get up to 1 TB of processed data per month and some free credits to spend on Google Cloud during the first 90 days. You can probably guess that BigQuery is billed by the amount of processed data.

BigQuery web console in Google Cloud, with the most important information being: "Query complete (2.3 sec elapsed, 2.1 GB processed)."
So, let's see what datasets are waiting to be explored! 🦠
What are BigQuery Public Datasets?
BigQuery public datasets are made available without any restrictions to all Google Cloud users. Google pays for the storage of these datasets. You can use them to learn how to work with BigQuery or even build your application on top of them, exactly as we're going to do.
You could query them just if they were your own. However, always pay attention to the license and other relevant info, like update frequency and last update date. Unfortunately, some datasets are really outdated:

So, what to expect? Some of these 212 public datasets are quite interesting:
- 28 datasets about climate, including the Real-time Air Quality dataset
- 24 datasets related to developer tools, including GitHub Activity Data
- 33 datasets marked encyclopedic, including Hacker News dataset
- and 33 datasets for COVID-19 research — let's talk about them!
COVID-19 Government Response Tracker. This dataset is maintained by the University of Oxford Blavatnik School of Government. It tracks policy responses to COVID-19 from governments around the world. Basically, all lockdowns, curfews, and workplace closures worldwide are registered in this dataset.
Google Community Mobility Reports. This dataset is maintained by Google. It provides insights into what has changed in people's habits and behavior in response to policies aimed at combating COVID-19. It reports movement trends over time by geography, across different retail and recreation categories, groceries and pharmacies, parks, transit stations, workplaces, and residential.
We can use both datasets to visualize and correlate the time measures against COVID-19 with changes in social mobility. Here's how it might look like:

Want to try it? Here's the live demo you can use right away. Also, the full source code is on GitHub.
For that, we need to create an analytical API over BigQuery and a web application talking to that API. So, let's get hacking! 🦠
How to Create an Analytical API
Why do we need an API in the first place?
The most obvious reason is that BigQuery can't provide a sub-second query response time, meaning that an application that talks directly to BigQuery will have a suboptimal user experience. Also, BigQuery bills you by the amount of transferred data, so if you have a popular app, you might suddenly know about that from a billing alert.
Also, direct interaction with BigQuery means that you'll need to write SQL queries. There's nothing wrong with SQL; it's a great domain-specific language, but having SQL queries all over your codebase smells like a leaky abstraction — your application layers will know about column names and data types in your database.
So, what are we going to do? In this tutorial, we'll use Cube.
Cube is an open-source analytical API platform, and it allows you to create an API over any database, BigQuery included.
Cube provides an abstraction called a "semantic layer," or a "data schema," which encapsulates database-specific things, generates SQL queries for you, and lets you use high-level, domain-specific identifiers to work with data.
Also, Cube has a built-in caching layer that provides predictable, low-latency response query times. It means that an API built with Cube is a perfect middleware between your database and your analytical app.
Let's try it in action.
The first step is to create a new Cube project. Here, I assume that you already have Node.js installed on your machine. Note that you can also use Docker to run Cube. Run in your console:
Now you have your new Cube project in the bigquery-public-datasets folder containing a few files. Let's navigate to this folder.
The second step is to add BigQuery and Google Cloud credentials to the .env file. Cube will pick up its configuration options from this file. Make sure your .env file looks like this:
Here's what all these options mean and how to fill them:
- Obviously,
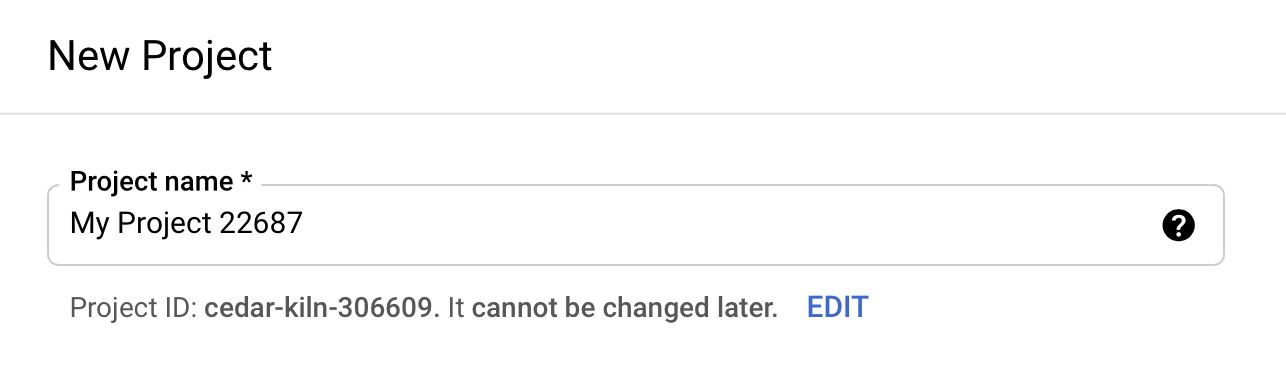
CUBEJS_DB_TYPEsays we'll be connecting to BigQuery. CUBEJS_DB_BQ_PROJECT_IDshould be set to the identifier of your project in Google Cloud. First, go to the web console of Google Cloud. Create an account if you don't have one. Then go to the new project creation page and create one. Your project identifier is just below the name text field:
CUBEJS_DB_BQ_KEY_FILEshould be set to the key file name for your Google Cloud user that will connect to BigQuery. It's better to use a service account, a special kind of Google Cloud account with restricted access. Go to the service account creation page and create one. On the second step, you'll be asked to specify the roles for this service account. The only roles needed for read-only access to public datasets areBigQuery Data ViewerandBigQuery Job User. After the user is created, you need to add a new authentication key — use the...button on the right to manage the keys for this account and add a new one of JSON type. The key file will be automatically downloaded to your machine. Please put it in thebigquery-public-datasetsfolder and update your.envfile with its name.

- The rest of the options configure Cube and have nothing to do with BigQuery. Save your
.envfile.
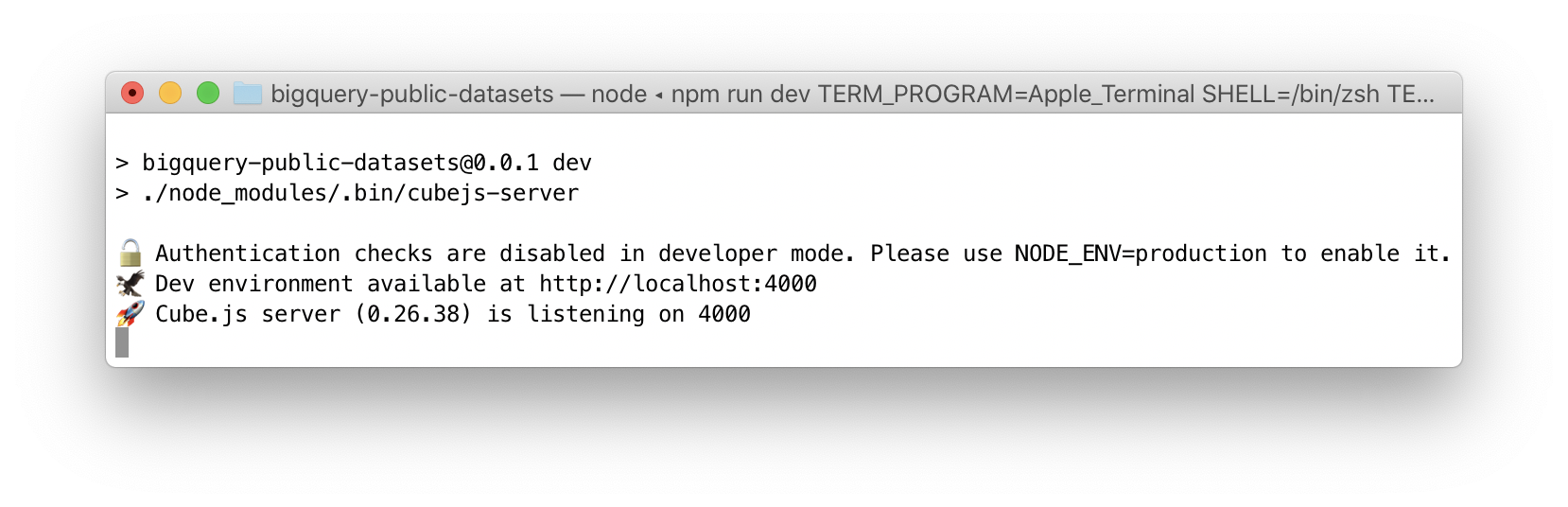
The third step is to start Cube. Run in your console:
And that's it! Here's what you should see:
Great, the API is up and running. Let's describe our data! 🦠
How to Define a Data Schema
Before we can explore the data, we need to describe it with a data schema. The data schema is a high-level domain-specific description of your data. It allows you to skip writing SQL queries and rely on Cube query generation engine.
Create two schema files with the following contents: take schema/Measures.js from this file, and schema/Mobility.js from that file. Here is a redacted version of the first file with a few interesting things:
Note that:
- in this data schema, you describe an analytical
cube - it contains the data retrieved via a straightforward
sqlquery - you can define
measures, i.e., numerical values to be calculated - measures are calculated using various functions, such as
max - you can define
dimensions, i.e., attributes for which the measures are calculated - dimensions can have different data types, such as
stringortime - in measure and dimension definitions, you can use BigQuery functions, e.g.,
CAST(... AS NUMERIC)orTIMESTAMP
And here's a part of another file:
Here you can see that our two cubes, based on different tables from different BigQuery datasets, are joined together with join, where a join condition is provided as an SQL statement. Cube takes care of the rest.
Now we have the data schema in place, and we can explore the data! 🦠
How to Explore the Data
As the console output suggests, let's navigate to localhost:4000 and behold Cube Developer Playground. It provides a lot of features, but we have a clear path to follow. Let's build a query.
To do so, go to the "Build" tab, click "+ Measure," and select a measure. For example, select Measures Confirmed Cases. As you can see, the Measures Date time dimension has been automatically selected, and the chart below displays the count of confirmed COVID-19 cases over time. You can even "+ Filter" by Measures Country, use the "equals" condition, and put your own country's name into the filter field. Looks interesting, right?

Definitely feel free to experiment and try your own queries, measures, dimensions, time dimensions, granularities, and filters.
After that, let's move on and build an analytical app! 🦠
How to Build an Analytical App
It's worth noting that Cube Developer Playground has one more feature to explore.
If you go to the "Dashboard App" tab, you'll be able to generate the code for a front-end application with a dashboard. There're various templates for different frameworks (React and Angular included) and charting libraries there. Still, you can always choose to "create your own," and if you choose a "dynamic" template, you'll be able to compose queries and add charts just like you did.

However, we'll choose a much simpler way to go from zero to a full-fledged analytical app — we'll grab the code from GitHub:
- first, download this dashboard-app.zip file
- unzip it to your
bigquery-public-datasetsfolder - run
yarnandyarn start(ornpm installandnpm start)
You should be all set! Navigate to localhost:3000 and have a look at this app:

Choose your country and take your time to explore the impact of COVID-19 and how mitigation measures correlate with social mobility.
Let's take Israel. You can clearly see three waves and the "easing" effect of "stay at home" requirements — after they are introduced, every wave spreads with lesser speed.

Let's take Germany. You can see how Germans interact with the rules: after the first "stay at home" requirements are lifted, park activity grows, and after the second "stay at home" requirements are introduced, parks instantly become deserted.

Let's take Singapore. Obviously enough, you can see Singapore doing a great job containing the virus. The third wave is nearly unexistent.

What are your own insights? Please share them in the comments!
And now, let's explore a few crucial parts of this app to understand better how it works and, more specifically, how it retrieves data from Cube API.
First, as you can see from package.json, it's obviously a React app created with the create-react-app utility. It has an index.js as an entry point and the App root component.
Second, it references @cubejs-client/core and @cubejs-client/react packages as dependencies. Here's what you can see in the api.js file:
Believe it or not, that's the bare minimum we should know about working with Cube REST API in the front-end apps. You import a client library, you compose your query as a JSON object, you load the result asynchronously, and you do whatever you want with the data.
In this application, the data is visualized with Chart.js, a great data visualization library. However, you can choose any library you're familiar with. And maybe your app will look even better than this one:

And that's all, folks! 🦠 I hope you liked this tutorial 🤗
Here's just a few things you can do in the end:
- go to the Cube repo on GitHub and give it a star ⭐️
- share a link to this tutorial on social media or with a friend 🙋♀️
- share your insights about the impact of COVID-19 in Cube community Slack


