
We've made a lot of changes to our product in the last twelve months, and I think it's a good moment to step back and write about them. This post is partly a reflection on how we got here, and partly a way to share how I think about the future of both our open source project and our commercial product.
The semantic layer wasn't a new idea when we started Cube. It had always been part of business intelligence. Every BI tool of the previous generation, from SAP BusinessObjects to Cognos to Microsoft Analysis Services, had some form of semantic layer built into it. The job of that layer was the same in all of them: enable self-serve analysis and provide governance.
Data teams would model the data, define measures, dimensions, and joins, and organize everything into user-facing objects business consumers could understand — universes in BusinessObjects, explores in Looker, with variants of the same idea in every other tool. Those objects got published as the analytics artifacts the rest of the organization used to go point-and-click their way to insights.
When we started Cube in 2019, the first thing we wanted to do was move the semantic layer itself into code. The industry was already heading that direction. LookML was a code-first semantic layer within Looker, and dbt was making the case for transformations as code. Treating analytics infrastructure like software — version control, code review, CI — was on its way to becoming the default. Defining the semantic layer the same way fit naturally inside that shift.
The stack itself was also fragmenting. The bundled BI suite — one tool that owned warehouse access, modeling, and visualization in a single package — was giving way to a stack of specialized tools, and visualization in particular was exploding: charting libraries, dashboarding products, vertical analytics apps, embedded analytics inside SaaS products. A semantic layer tied to one BI tool wasn't going to hold up in that world, because every other tool downstream would end up needing its own copy of the model.
So we built Cube as a standalone semantic layer: the model defined in code, in one place, with any tool downstream consuming it through APIs. Because the semantic layer is fundamentally a BI building block, Cube ended up serving the two classic BI use cases from day one — embedded analytics and internal BI. We even called Cube "headless BI" on the homepage for a while to make the BI lineage explicit.
The open source project grew quickly, and in 2021 we built a commercial entity around it. The commercial product was the same headless BI, packaged with more features and an easier path to deploying and operating it at scale.
The agentic moment
Fast-forward to the post-COVID years, and AI started reshaping every category of software. It became clear that the future of business intelligence is going to be agentic. The BI workflow is starting to look like a multiplayer game where humans and AI agents collaborate on different analytics tasks: building and testing data models, exploring data, finding insights, and packaging those insights into dashboards and apps.
In that agentic future, the semantic layer becomes more important, not less. The same governance and self-serve principles that the semantic layer brought to humans apply equally to agents. Agents need context to answer questions correctly — what "active customer" means in your business, how spend rolls up, which permissions apply to which rows — and that context lives in the semantic layer. Without it, an agent connected to a warehouse will write SQL that runs and returns numbers that don't match how your business actually defines its metrics.
That made us see a unique opportunity for Cube: build out the remaining parts of business intelligence and become the full platform. That's the journey we embarked on a year and a half ago, and by the end of last year we shipped the first version of our agentic analytics platform.
So what started as one part of BI became the whole thing. That also gives us a clean frame for how we now think about the future of the open source project and the commercial product.
In short: Cube Core remains open source. It's the semantic layer piece of the full agentic analytics platform we call Cube, and it's what we run ourselves internally for the core semantic layer workload — data modeling, access control, caching, and the APIs that support all of it. Cube (the commercial cloud product) is the full-featured agentic analytics platform, built on top of Cube Core, and it's what you use when you want internal BI or customer-facing embedded analytics out of the box.
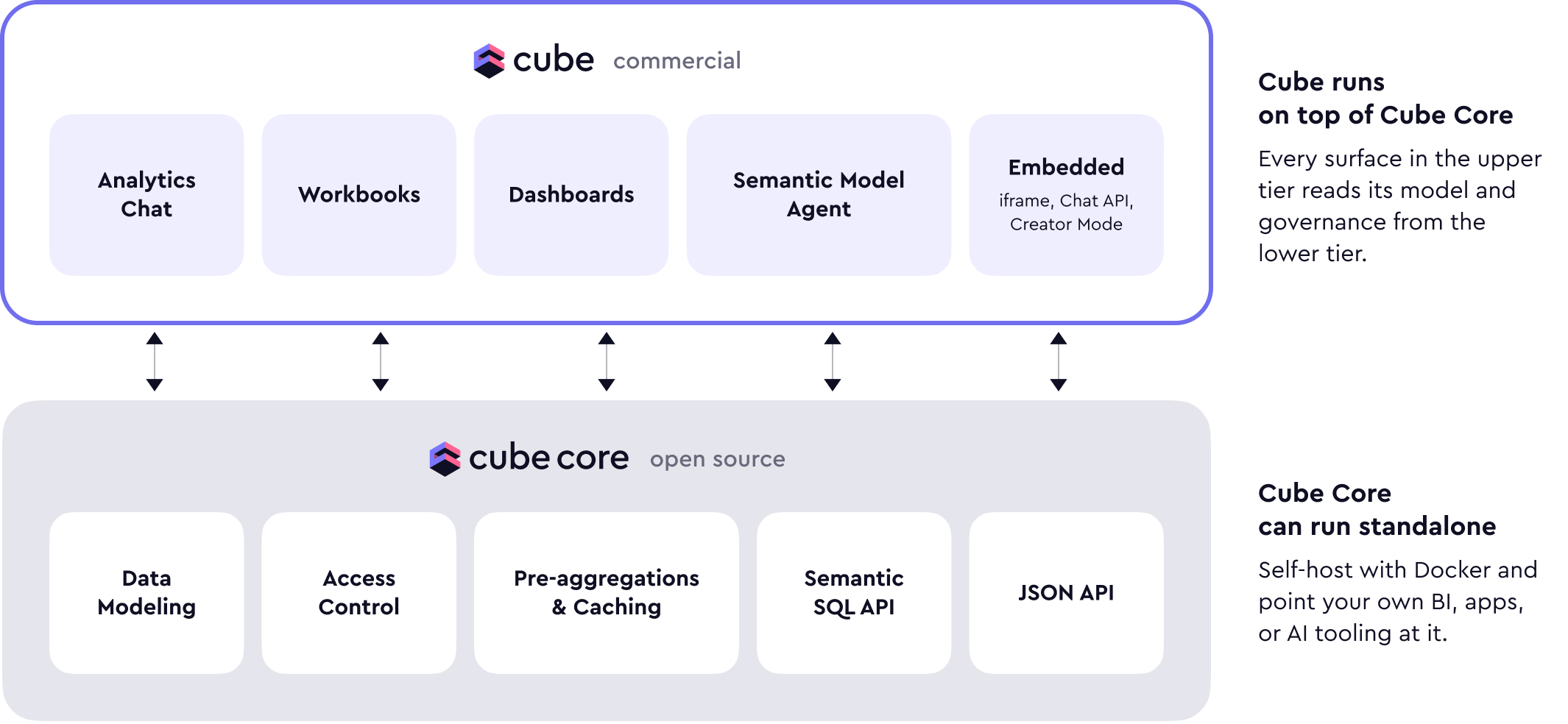
Cube Core
Cube Core is largely unchanged in its purpose, and we keep adding features, improving performance, and tightening stability.
The biggest thing in flight is a Rust rewrite of the core engine, which we call Tesseract. Tesseract brings multi-stage data model support (period-over-period, percentage of total, running aggregates) and is also aimed at improving the performance of many Cube Core internals — SQL generation and data model compilation in particular. We've written separately about Tesseract and how the new engine works; we're nearing the completion of that rewrite.
The rest of the Cube Core roadmap is steady and focused on the foundations:
- Data modeling. New modeling primitives, better composition, faster compilation.
- Access control. More expressive row- and column-level policies, easier multi-tenancy.
- Pre-aggregations. Smarter matching, better refresh, broader engine coverage.
We're also investing heavily in the SQL API, which now supports HTTP transport, and we consider it the primary Cube Core API going forward. If you're starting a new project or evaluating Cube Core today, I'd recommend the SQL API over our older JSON-based REST API.
The reason is the expressiveness of SQL. Semantic layers have always had to balance governance and flexibility. Lock the model down too tight and every new dimension or measure becomes a ticket to the data team — that kills the self-serve part of the value. Open the model up and give consumers raw SQL to the warehouse and you lose the governance entirely. The right balance, as far as we can tell, is a semantic layer that supports ad-hoc extensions on top of the governed metrics. That's the design behind our Semantic SQL API: it's a Postgres-compatible interface where you can query measures and dimensions, and then build SQL-based calculations on top of those. You can compose new metrics inside a single query, and later, if they're useful, promote them into the data model. Consumers stay inside the governed layer while still being able to reach for the flexibility they need.
The JSON REST API doesn't have that. It's essentially a list of available measures and dimensions and a way to query them. We don't think it makes sense to re-implement a calculation language inside a JSON envelope, which is why we're pointing new development toward the SQL API. The older API isn't going anywhere; we're just not adding new capabilities to it.
Zooming out, the use cases for Cube Core are the same as they've always been: embedded analytics and BI.
Cube Core is a great fit when you need to build your own BI experience — a vertical, domain-specific BI tool where your value is in the domain and you want a proven semantic foundation underneath you instead of reimplementing one from scratch.
The other strong fit is deeply customized embedded analytics, especially when the integration has to live inside your product and your deployment topology is non-standard. A lot of our open source users have built impressive embedded experiences this way, and we'll continue to support that.
Cube
Cube — the cloud product — is our fully featured agentic BI platform. We run Cube Core inside Cube and wrap all the higher-level features and the AI orchestration on top of it. Cube Core inside Cube is the same Cube Core that's open source. The data model is fully compatible both ways: you can take a model built in the cloud product and run it in your own Cube Core deployment, and vice versa.
If you want a quick tour of what's in Cube today, we recently ran a workshop walking through the agentic analytics workflow end to end:
Like Cube Core, Cube serves two primary use cases: internal analytics and customer-facing embedded analytics. The difference is that with Cube you get the full platform — the frontend, the integrations, the deployment automation, the AI orchestration — instead of just the semantic layer.
If you're looking for an internal BI platform that's modern, AI-native, and built on a strong open source foundation, that's what Cube is. We continue to invest heavily in the internal BI use case: AI-driven exploration, dashboarding, role-based access, integrations with the rest of the data stack. Given our history as a universal semantic layer, we also maintain strong integrations with other BI tools — Tableau, Power BI, and others. Most organizations don't standardize on a single BI tool, and we want Cube to be the layer that ties them together rather than forcing teams to pick.
We've also invested heavily in our Excel and Google Sheets integrations to support finance teams and anyone whose primary working environment is a spreadsheet. The semantic layer is what makes those integrations useful — the same definitions and access policies apply whether the user is in a dashboard, in a chat, or in a pivot table.
Finally, given how much of our customer base runs on embedded analytics, we're doubling down on that side of Cube as well. We're rolling out more ways to embed Cube into your product — from drop-in iframes to the underlying APIs, with options in between for teams that want something in the middle. Different products need different levels of control, and we want every level to be a first-class option.
If you're building a SaaS product and need embedded analytics, Cube Cloud is the path I'd recommend by default. You get the levels of customization you need, and we take on a lot of the operational complexity that comes with multi-tenant analytics at scale.
Cube Core is still a strong choice for embedded analytics if you're willing to invest engineering resources into building the analytics experience yourself, or if analytics is the core value of your application — for example, if you're building a niche vertical BI tool. In those cases, owning the stack with Cube Core makes sense.
If your core expertise is elsewhere — like our customers at Brex, Webflow, and Deel — but you still need embedded analytics inside your product, Cube Cloud is the faster path. We take on the complexity, and you get to focus on your product.
What's next
I'm excited about the future of both Cube Core and Cube. They're built around the same semantic layer, they share the same data model, and they each have a clear, valid use case. We'll keep investing in both.
If you have questions about which one fits your project, find me on LinkedIn or come say hi in our Slack community — I'm always happy to talk with customers and the open source community.